
软件质量

AI时代,“人月神话”能被打破吗?
本文基于 Wes McKinney《Mythical Agent Month》原文,提炼 AI 智能体对软件工程的核心影响,并从软件质量视角解读:AI 并未打破人月神话,反而让概念完整性、架构质量、技术债务等问题更加突出。
阅读详情 "AI时代,“人月神话”能被打破吗?"

数智化,只是IT技术部门的事吗?
技术只是翻译官,业务才是指挥官。本文用最白话的方式提醒:数智化不是 IT 部门的家务事,而是管理者重构业务思维的必修课。
阅读详情 "数智化,只是IT技术部门的事吗?"
不用懂技术,普通人如何用“数字思维”解决工作中的乱麻?
数字化不是程序员的专利。很多职场人的焦虑,其实源于工作边界不清、反馈缺失。本文跳出代码和工具的限制,为非技术人员拆解三套最实用的“数字思维”:量化指标、颗粒度拆解、闭环意识。带你从一团乱麻的工作中,找回久违的掌控感。
阅读详情 "不用懂技术,普通人如何用“数字思维”解决工作中的乱麻?"

为什么公司用上了强大的系统,大家却在偷偷用回Excel?
很多老板寄希望于通过强大的系统实现“降本增效”,结果却换来了一线员工的怨声载道。为什么斥资巨投的数字化系统最后成了摆设,大家反而偷偷用回了 Excel?本文深度拆解转型背后的三大错位,带你揭开数字化“形式主义”的真相。
阅读详情 "为什么公司用上了强大的系统,大家却在偷偷用回Excel?"
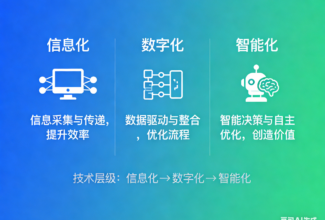
信息化、数字化和智能化,是你理解的那样吗?
一篇文章带你跳出认知误区,看懂科技转型的三个真实阶段:信息化、数字化、智能化。
阅读详情 "信息化、数字化和智能化,是你理解的那样吗?"

AI时代,请收好这份从认知到行动的「团队为质量负责」全方位指南
本文旨在为团队提供一套从认知到行动的完整框架:首先,帮助团队统一对质量多维度的理解;其次,指导如何打破角色壁垒,建立全员质量共识与文化;接着,详细介绍了构建有效质量协作机制的关键实践,如测试左移、持续反馈等;并重新定义了QA作为“质量倡导者”的赋能角色。最终,文章强调,通过将质量责任融入团队的每个环节,才能打造出真正高效、抗风险的质量保障能力,这正是企业在AI时代稳健前行的核心竞争力。
阅读详情 "AI时代,请收好这份从认知到行动的「团队为质量负责」全方位指南"

AI辅助软件质量:跑不快,是因为你还跑得不够慢
“跑不快,是因为你跑得还不够慢”这一跑步哲学,精准揭示了AI赋能软件质量的真相。AI并非万能仙丹,企业盲目引入AI不仅无法提升质效,反而可能导致“受伤”。本文旨在为热衷AI的企业提一个醒:在追求“快”之前,先回归“慢”的修炼,方能让人工智能在坚实的土壤中真正绽放价值。
阅读详情 "AI辅助软件质量:跑不快,是因为你还跑得不够慢"

2025年软件测试的演进:一份全面分析报告(译)
这篇文章指出,2025年的软件测试正在经历全面变革,从传统的事后质量检查,升级为企业的战略性竞争优势。
阅读详情 "2025年软件测试的演进:一份全面分析报告(译)"
育见自己
一个简单动作,让你瞬间从一团乱麻中解放出来
在焦虑无助、思绪纷杂时,我们常陷入越想越乱的困境。本文提出一个简单有效的方法:将经历和感受写下来。
阅读详情 "一个简单动作,让你瞬间从一团乱麻中解放出来"

守护孩子的成长光芒:父母最应该常说的8句话
想让孩子勇敢、自信又阳光?其实秘密就在父母的日常语言中。这8句简单却充满力量的话,能够在孩子心中种下信心的种子,培养面对困难的勇气,守护他们健康成长的光芒。
阅读详情 "守护孩子的成长光芒:父母最应该常说的8句话"

珍·古道尔的传奇告诉我们:孩子的未来,藏在父母的教育智慧里
“课本上的传奇”珍·古道尔的传奇人生揭示了家庭教育的真谛。本文通过她母亲如何呵护她的好奇心、支持她的非洲梦想等真实故事,为现代父母提供教育启示:孩子的未来,藏在父母的教育智慧里。
阅读详情 "珍·古道尔的传奇告诉我们:孩子的未来,藏在父母的教育智慧里"

为什么你越要求,孩子越不听话?
为什么你越要求,孩子越不听话?许多家长都陷入了“高期待、低支持”的育儿陷阱。就像老板只说“把报告做好”,却不告诉具体怎么做一样,我们对孩子的要求也常常含糊不清。这篇文章将告诉你如何改变这种模式,用具体、明确的指令,帮助孩子建立自信,激发他们的内驱力,成为真正的“别人家的孩子”。
阅读详情 "为什么你越要求,孩子越不听话?"